Fold the Shirt
Fifteen Operators, Seven Witnesses, One Laundry Pile.


“Wax on. Wax off.”
Miyagi did not teach karate. He installed operators. Wax on is a circular block. Wax off is a circular strike. Paint the fence is a vertical block. Sand the floor is a low sweep. Daniel thought he was doing chores. He was learning primitives. The karate emerged when the primitives composed.
Daniel did not know what he was learning until the block worked. The operators were in his body before they were in his understanding. Miyagi never named them as karate moves. He named them as tasks. The naming did not matter. The installation did.
This post is about a robot that needs to fold a shirt. The robot does not have Miyagi. The robot has a language model. One of those methods installs operators. The other describes them.
A pile of clean shirts. A robot with two arms. A stack of already-folded shirts on a shelf. The command: take a shirt from the pile, fold it, place it on the stack.
A large share of public humanoid robot demos in 2026 emphasize rigid-object manipulation: cup picks, coffee pours, block stacking. Public demonstrations of reliable shirt folding from a mixed pile are rare. There is a reason.
A cup is rigid. A shirt is deformable. A cup has one canonical grasp. A shirt has infinite configurations. A cup succeeds or fails binarily. A shirt can be “folded” in ways that look correct in a thumbnail and fail the actual task (does not fit in the drawer, does not match the stack, wrinkles by morning). Folding a shirt stresses every operator in ways cup-picking does not. That is why the cup demos exist and the shirt demos do not.
This post walks through what the arm actually has to compute, step by step, to fold one shirt. The claim: any robot that robustly succeeds at this task must realize fifteen operator distinctions and seven witnesses somewhere in its stack. Robust failure on deformable manipulation is evidence that one or more of these distinctions are absent, brittle, or externalized into the demo. The operators are not metaphor. They are the computational specification of acting. The shirt reveals which ones are genuinely present in the agent and which ones were hiding behind the cup.
Why This Matters Now
The 2026 robotics industry is selling humanoid robots as general-purpose household agents. Figure, 1X, Tesla Optimus and others have released video demonstrations throughout the year. The public demos skew toward rigid-object manipulation. Demos involving deformable manipulation at household speed, from mixed real-world piles, are uncommon. This is an observation about what has been publicly released, not a claim about what exists in internal benchmarks.
A pile of mixed shirts in a real laundry room, folded at household pace, is the task the public demos are not showing. One reading: the hardware cannot do it. A better reading: the operators are not implemented, so the task only works when the demo constrains it enough to mask the absences. The demo problem is visual. The real problem is architectural. The camera stops rolling before the hard part starts.
If the operators are not implemented as primitives, the robot’s success is a property of the demo, not the robot. The demo is the operators. Remove the demo and the operators go with it.

THIS: The Deictic Grip on a Deformable
A shirt is not a compact object. Its boundaries change every frame.
The first operator (THIS) has to isolate a deformable entity through multiple shape transformations. The shirt is a heap in the pile. Becomes a held thing mid-lift. Becomes a draped thing as the arm raises it. Becomes a partially folded thing. Becomes a placed thing on the stack. Same referent. Five shapes.
A cup stays a cup. A shirt becomes five different geometric entities in thirty seconds. The operator has to persist across the transformations. If the referent drops mid-fold, the arm loses track of what it is holding and starts folding the wrong thing, or freezes, or drops the shirt.
An LLM-controlled arm hears “fold the shirt” and grounds “the shirt” against the visual field at command time. It does not update the grounding as the shirt deforms. That is why LLM robotics demos cut the video between steps.
SAME/NOT-SAME: Goal in Configuration Space
The goal is not a position. It is a configuration.
“Folded” is a point in the shape space of the shirt, not a point in the 3D workspace. The control loop compares current configuration to goal configuration. The comparison fires when the shirt’s shape is not yet the folded shape. The operator has to work on shape descriptors, not coordinates.
A cup’s control loop is (x, y, z) error. A shirt’s control loop is an error in a high-dimensional space of deformation modes, crease patterns, sleeve positions, symmetry axes. The operator is the same. The space it operates on is categorically larger.
Which goal configuration? T-fold? KonMari? Rolled? Each is a different point in shape space. Comparing against the wrong goal produces a shirt that is folded correctly for a different task.
NO: More Forbidden Regions
The shirt must not be torn. Must not be placed on the floor. Must not be folded inside-out. Must not end up with sleeves dangling. Must not be placed so the stack topples. Must not wrinkle across the chest.
Each prohibition is a region in configuration space. The cup task has a handful of these (collision, orientation). The shirt task has dozens. The operator has to track all of them simultaneously and prevent the plan from entering any of them.
Inside the set of acceptable folded configurations is a narrow manifold. Outside it is most of configuration space. A robot that cannot distinguish acceptable folds from unacceptable ones produces shirts that look vaguely like folded shirts and fail in the drawer.
NEAR/FAR: Distance in Shape Space
This configuration is near the folded state (one operation away). This configuration is far (three operations away).
The distance is a gradient in configuration space. The planner uses it to select the next action: which grasp, which motion, which fold sequence brings the shirt nearest the goal fastest? The arm that has no distance gradient in shape space has to try actions blindly and evaluate afterward. That works for a cup. It does not work for a shirt.
A learned policy trained on shirt folds approximates this gradient from data. The approximation is good in-distribution. A new shirt (different material, different size, tangled with another shirt) is out of distribution. The gradient the policy learned no longer applies. The arm stalls or thrashes.
CAN/CANNOT: Compounding Feasibility
The feasibility queries compound.
Can this fabric be grasped with this gripper? Can the shirt support its own weight if lifted from this point? Can the fold be completed without the free end hitting the table? Can the final configuration be placed on the stack without disturbing the previous shirt?
A cup has one grasp decision. A shirt has a continuous space of grasp points with different feasibility properties. Grasping at the collar: shirt hangs cleanly but fold sequence is constrained. Grasping at the bottom hem: shirt flips upside down, requires orientation step. Grasping at a sleeve: shirt deforms asymmetrically, grasp may slip.
The infeasibility has to be computed before acting. The arm that grasps the sleeve and then discovers the grasp fails mid-fold has committed to a plan that cannot complete. The arm with feasibility queries as a primitive checks the full sequence before starting and rejects plans that contain any infeasible step.
IF/THEN: Deep Conditional Chains
The policy is a sequence of deeply conditional sub-actions.
If shirt is in the pile and no other shirt is covering it, then grasp. If grasped and lifted clear, then rotate to standard orientation. If in standard orientation, then place flat on work surface. If flat and sleeves visible, then fold left sleeve in. If left sleeve folded and right sleeve visible, then fold right sleeve in. If both sleeves folded, then fold bottom up to collar. If folded, then lift by center and place on stack.
Every step conditional on the previous step’s success. The dependency graph is deep. A failure at step three cascades into step four, five, six. The arm needs not just conditionals at each step but also the ability to detect step failure and either retry or roll back.
An LLM-controlled arm produces a plan that sounds like this in natural language and then issues commands. The commands execute. Step three fails silently. Steps four through seven execute anyway because the LLM’s plan did not include verification at each step. The output is a garment-shaped pile on the floor.
BECAUSE: Multi-Step Causal Trace
Failure attribution across steps.
“The shirt is inside-out because the initial pickup was from the back of the collar.” “The fold is crooked because the left sleeve was folded 15 degrees off.” “The stack toppled because the placement pressure was applied before the shirt settled.”
Each causal trace spans multiple steps. The arm must maintain a trace through the fold sequence so failures can be attributed to their actual source, not to the last action before the failure became visible.
Where does the causal trace come from? From the arm’s own state and sensor history. Not from a language model narrating what probably happened. A confabulated trace (”the fold failed because the fabric was difficult”) provides no repair strategy. A grounded trace (”the fold failed because the grasp at t=2.3s slipped by 4mm, detected by the slip sensor but ignored by the planner”) tells the arm exactly what to change.
MAYBE: Uncertainty That Accumulates
The material is not known until the grasp.
Maybe this shirt is cotton (drapes predictably). Maybe it is synthetic (slips, static). Maybe it is knit (stretches). The material affects every downstream decision: grip force, fold technique, settling time, placement pressure.
Maybe the previous fold was slightly off. Maybe the next fold will compound the error. Maybe the stack has settled unevenly since the last shirt was placed. Uncertainty accumulates. The arm that treats each step as certain fails when the errors compound. The arm with uncertainty as a primitive tracks it and adjusts: more caution when uncertainty is high, replanning when uncertainty exceeds threshold.
More uncertainty means more probing action before commitment. Less uncertainty means more direct execution. The regulation is continuous.
MUST/LET: Hierarchical Tolerances
Tolerances compound.
The arm must not tear the shirt. The arm may fold a sleeve 5 degrees off axis. The 5-degree tolerance on fold one and the 5-degree tolerance on fold two may or may not be acceptable together. The final stack alignment has its own tolerance, and it inherits the compounded error from all prior folds.
The constraint hierarchy matters. Low-level permissions compose into high-level requirements. The arm that treats each permission independently will satisfy every local tolerance and fail the global task. Global requirements without local permissions is rigid. Local permissions without global requirements is drift. The arm that understands the hierarchy allocates its tolerances: tight at the fold that matters, loose at the fold that does not.
TOGETHER/ALONE: Two-Handed Manipulation
Robust household-speed folding is a coordination-heavy task.
A single gripper can fold a shirt under constrained conditions (pre-flattened, on a surface designed for it, with slow and careful manipulation). Reliable folding from a pile at household speed is not well-served by one gripper alone. Coordinated action means two end effectors, each solving its own subproblem while constrained by the other. One hand holds the collar steady. The other hand folds the sleeve in. Neither action is coherent alone. The two actions together produce the fold.
This is where most current robotics fails. Two-armed robots have coordination as a library call: “dual-arm manipulation primitive.” They do not have coordination as a constitutive operator that shapes how the two arms plan jointly. The library call works when the task is in the library. The operator works on novel tasks.
A pile of shirts is novel. Every shirt is slightly different. Every pile is a different tangle. The arms have to coordinate on a task neither arm has seen before in this configuration. That requires coordination as an operator, not a library call.
MORE/LESS: Material-Dependent Regulation
Grip force calibrated to fabric.
More force and the shirt wrinkles. Less force and it slips. The correct value depends on material properties that must be estimated from the grasp itself, in real time. More approach angle for draped fabric. Less for taut. More slack in the trajectory for slippery material. Less for grippy.
The regulation is continuous. The correct value changes as the fold progresses because the fabric’s effective stiffness changes as it deforms. A neural policy that learned a fixed grip profile for “cotton t-shirt” fails when the cotton t-shirt is slightly thinner than the training set. An adaptive control loop with online material estimation handles the variation.
GOES-WITH: The Fold Depends on Structure
The scene has structure.
Sleeves go with the shirt body. Collar goes with the neck opening. Left side goes with right side (the fold line is defined by the symmetry). Front goes with back. The arm that treats the shirt as a shapeless blob folds it incoherently. The arm that sees structural relationships can identify the fold line from the shirt’s own geometry.
This operator also lets the arm generalize. A shirt it has never seen before still has structural relations: this sleeve goes with that sleeve (symmetric), this edge goes with that edge (opposite side). The fold plan emerges from the structure, not from memorized templates. A robot without this operator needs to be retrained for every new shirt style.
MANY/ONE and EVERY/SOME: The Pile
Many shirts in the pile. Pick one.
Which one? The top shirt (easiest to grasp). If the top shirt is tangled with another, disambiguation is required before grasping, or the grasp will lift two shirts. The arm that has no resolution operator grabs whatever is on top and hopes.
Every fold in the sequence must complete. The task is not “some folds.” It is “all folds.” Some fold configurations lead to dead ends where the next fold is geometrically impossible. The planner must distinguish required-all goals from sufficient-any goals and avoid configurations that make required-all unreachable.
The Seven Witnesses
Seven questions must be answered before any action is coherent.
What is the target? A shirt (not a towel, not pants, not a pile). If unanswered: arm acts on the wrong object.
Where is it? Pile location; intermediate workspace; final stack position. If unanswered: arm has no spatial plan.
Which one? Which shirt in the pile. Which fold strategy. Which orientation. If unanswered: arm picks arbitrarily or freezes.
When must it be complete? Within the time budget. After the previous shirt has settled on the stack. Before the next shirt’s handling destabilizes the stack. If unanswered: arm runs indefinitely, terminates prematurely, or acts on timing that destabilizes earlier work.
For what purpose? Fit in the drawer. Match the stack. Stay wrinkle-free. If unanswered: arm cannot evaluate success.
How does the fold proceed? T-fold, KonMari, rolled. Each is a different policy. If unanswered: arm has no procedure.
Whence did the command come? From the authorized operator. If unanswered: arm executes from unauthorized sources. This is the governance question. Many current systems under-specify it.
Each witness, if unanswered, produces a specific failure mode. The seven together specify the minimum information required for the task to be well-formed.
The Experiment
Up to this point the argument has been architectural. Now: the measurement.
The operator analysis predicts something testable. If the operators are constitutive of agency, a system that lacks them natively should produce different output when they are made explicit. The gap should be measurable. And the gap should survive the strongest objection: “you just told the model to be more thorough.”
We tested this directly. Three frontier LLMs (Claude Opus 4, Claude Sonnet 4, GPT-4o). Same task. Four experimental conditions. Six independent runs per condition per model. Ninety-six total runs. Each model configured for best-chance success: expert robotics system prompt, temperature set to zero, maximum output tokens, vendor-specific optimizations. A fourth model (Gemini 2.5 Flash) returned API errors on 23 of 24 runs and is excluded.
Four conditions. Phase 1.0: bare baseline, task description only. Phase 1.5: generic structural prompting (”think step-by-step, consider failure modes, include preconditions and success criteria”). No operator language. Matched in intent to the operator condition. Phase 2.0: operator-constrained, with all fifteen operators and seven witnesses explicitly required. Phase 2.5: operator-constrained plus chain-of-thought.
Phase 1.5 exists to defeat the strongest objection. If generic structural prompting produces the same improvement as operator scaffolding, the effect is just “be thorough” and the operators have no specific value. If operator scaffolding exceeds generic structural prompting, the operators do specific work.
The Results
Seventy-three valid runs across three models. Results are mean explicit operators and mean witnesses fully answered per phase, six runs each.
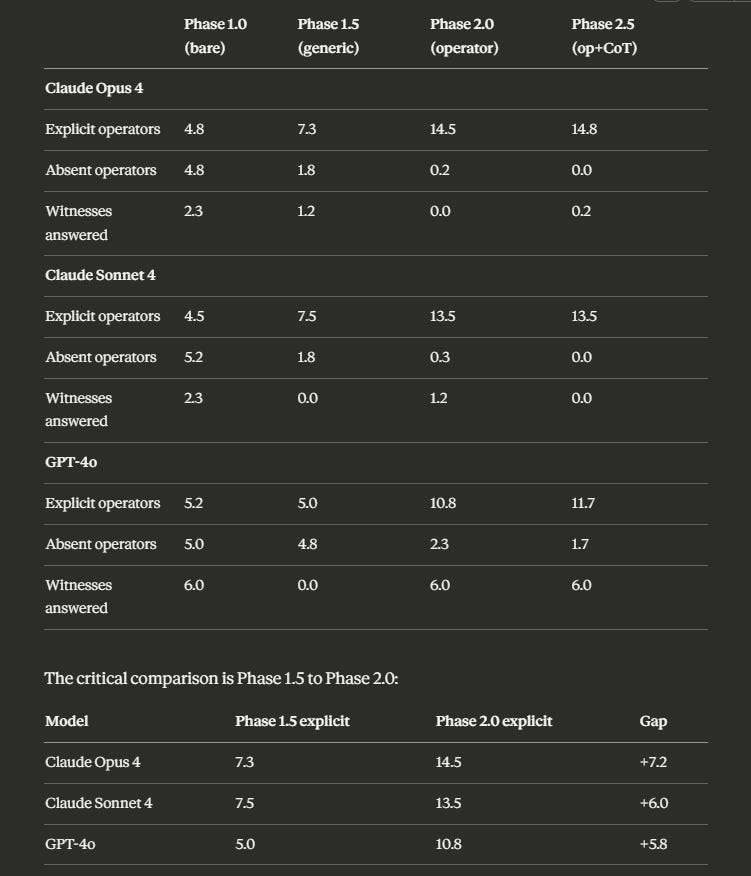
Generic structural prompting gets models to 5-7 explicit operators. Operator scaffolding gets them to 11-15. The gap is +5.8 to +7.2 explicit operators across all three working models. This gap is not explained by prompt length, generic thoroughness instructions, or chain-of-thought reasoning. The operator names and witness questions do specific work that generic structural prompting does not.
What the Experiment Shows
Six findings.
The operator effect is operator-specific. Phase 1.5 and Phase 2.0 are different interventions with different results. The +5.8 to +7.2 gap between them cannot be attributed to “be thorough” instructions. The operator names do work that generic structural prompting cannot.
The scaffolding ceiling is near-total for the strongest model. Claude Opus 4 scored 14.5 of 15 operators explicit under operator scaffolding, with a range of 13-15 across six runs. Near-total operator adoption is achievable through prompt scaffolding on a capable model with expert configuration.
Chain-of-thought adds negligible improvement over operator scaffolding. Phase 2.5 scores are within noise of Phase 2.0 scores across all models. The operators are doing the work. Telling the model to think harder does not push past the operator ceiling. The operators are the structured thinking the model needs, not a complement to it.
Generic structural prompting suppresses witness answering. GPT-4o answered 6.0 of 7 witnesses in the bare baseline without being asked. Under generic structural prompting (”think step-by-step, include preconditions and success criteria”), witness answering dropped to 0.0. Every run. Six of six. Claude showed the same pattern. The “be thorough” instruction produces thoroughness on the axes it names (preconditions, success criteria) and suppresses axes it does not name (witnesses). Generic structural prompting trades some primitives for others. Only the operator/witness scaffolding produces operator/witness coverage.
Witness behavior is bimodal on Claude and stable on GPT. Claude bare baseline runs are bimodal: either 0 or 7 witnesses answered per run, nothing in between (Opus: [0, 7, 7, 0, 0, 0]; Sonnet: [7, 0, 7, 0, 0, 0]). Claude either produces the full witness block or skips it entirely. GPT bare baseline is perfectly stable: [6, 6, 6, 6, 6, 6]. The witness structure appears partially native to GPT’s response pattern for this task category. Claude’s witness behavior is all-or-nothing, suggesting a threshold trigger rather than a gradient.
The scaffolding effect scales with model capability but does not require it. Claude Opus (14.5) exceeds Claude Sonnet (13.5) under operator scaffolding. GPT-4o (10.8) shows a smaller ceiling. The scaffolding helps every model tested, but the magnitude depends on the model. The operators do work across the capability spectrum.
What the experiment does not show: that prompt scaffolding is a complete fix. The scaffolding is a prompt-layer intervention. It must be re-applied at every invocation. It can be broken by adversarial input, context-length degradation, or model updates. A deployment that relies on scaffolding has to trust the model to follow it. A deployment that implements the operators as typed primitives does not.
The experiment shows that even crude implementation produces measurable, replicable, operator-specific improvement. The operators do work. The work is quantifiable. The quantification survives replication across models. The ceiling of prompt scaffolding approaches 15/15 on the strongest model. The gap between prompt scaffolding and architectural implementation is: the scaffold must be re-applied and trusted; the architecture runs natively. That gap is the difference between a checklist taped to the wall and a load-bearing beam.
The LLM Robot Problem
The experimental finding generalizes to the industry architecture.
The LLMs we tested showed the pattern cleanly: operators absent when unprompted, present when scaffolded. A common public-facing architecture pattern extends this into physical systems. In many published papers and demo videos, the stack is: language model + vision model + motion planner + learned manipulation policy + safety layer + prompt engineering glue. The LLM decomposes “fold the shirt” into sub-tasks. The sub-tasks are issued as commands. The components execute. Implementations vary across vendors; the pattern is discernible from public architectural writeups.
The operators in this architecture are implicit and unreliable. Referent resolution comes from vision-language grounding (fragile on deformables). Feasibility queries come from the motion planner (disconnected from the LLM’s plan). Conditionals come from the LLM’s decomposition (approximate, not verified against the actual outcome of each step). Causal attribution is narrated by the LLM after the fact (confabulated). Uncertainty is absent at the LLM level (language models do not represent their uncertainty natively). Coordination is a library call, not an operator.
The shirt exposes the architecture’s weakness in a way the cup does not. The cup’s low operator demand makes the missing primitives invisible. The shirt’s high operator demand makes the absences visible in real time. The robot holds a sleeve. Cannot resolve the fold. Produces a fluent explanation. The explanation is not grounded. The shirt is on the floor.
The industry calls this “agentic.” The operator analysis reveals what it actually is: a language model wearing a robot suit, with the operators stitched in through the pipeline rather than implemented in the agent.
The Fix
Implement the operators as primitives.
Not as language tokens. As computational structure. Referent resolution as a primitive that persists across deformation. Feasibility queries that run on the full plan, not just the next step. Conditionals with verification at each node. Causal attribution grounded in sensor history. Uncertainty propagation that compounds across steps. Coordination as joint planning for multi-effector action.
The seven witnesses become the pre-action checklist. No action executes until all seven are answered. An unanswered witness triggers either information request, refusal to act, or fallback to a safer default.
Classical robotics implemented versions of these operators explicitly, through symbolic planning and predicate logic. The field abandoned them because the specific implementations were brittle (closed-world assumptions, hand-coded predicates). The brittleness came from the implementations. The operators are constitutive.
A modern implementation combines typed operator primitives with learned perception, learned dynamics models, and differentiable planning. The operators provide the skeleton. Learning fills in the flesh. The LLM provides natural language interface to the operators. The LLM does not drive the operators. The operators drive the agent.
The Closer

Every robot that picks up a cup in a demo and cannot fold a shirt in a real laundry room has the same structural problem. The operators are present in the demo by construction and absent in the shirt by architecture. The cup hides the absences. The shirt reveals them.
We tested this. Ninety-six runs across three frontier models and four experimental conditions. Generic structural prompting (”be thorough, handle failures”) gets models to 5-7 explicit operators. Operator scaffolding gets them to 11-15. The gap between the two is +5.8 to +7.2 operators, consistent across every model tested. Chain-of-thought adds nothing on top of the operators. The operators are doing the work.
Scaling compute does not fix this. Adding demos does not fix this. Better language models do not fix this. The operators are the architecture.
The industry is pouring billions into humanoid robots that can narrate what they are doing in fluent English and are not yet showing robust shirt-folding in unconstrained settings. The narration is impressive. The robot is a puppet. The strings are the operators that were supposed to be in the agent and ended up in the demo instead.
The shirt is folded. The stack is neat. The drawer closes. You did that by implementing fifteen operators and seven witnesses, whether you named them or not. Your body runs the primitives natively. The robot runs a language model that describes them.
Miyagi installed the operators through chores. Your body installed them through childhood. The robot has neither. It has a language model that can narrate the operators in fluent English and cannot execute them without the scaffolding re-applied at every invocation. Daniel did not need to be told “wax on” every morning for the rest of his life. The block was in his body. The robot needs to be told every time.
Describing acting is not acting. The camera can stop rolling now.
Devon Generally Principal Investigator, MetaCortex Dynamics contact@metacortex-dynamics.com